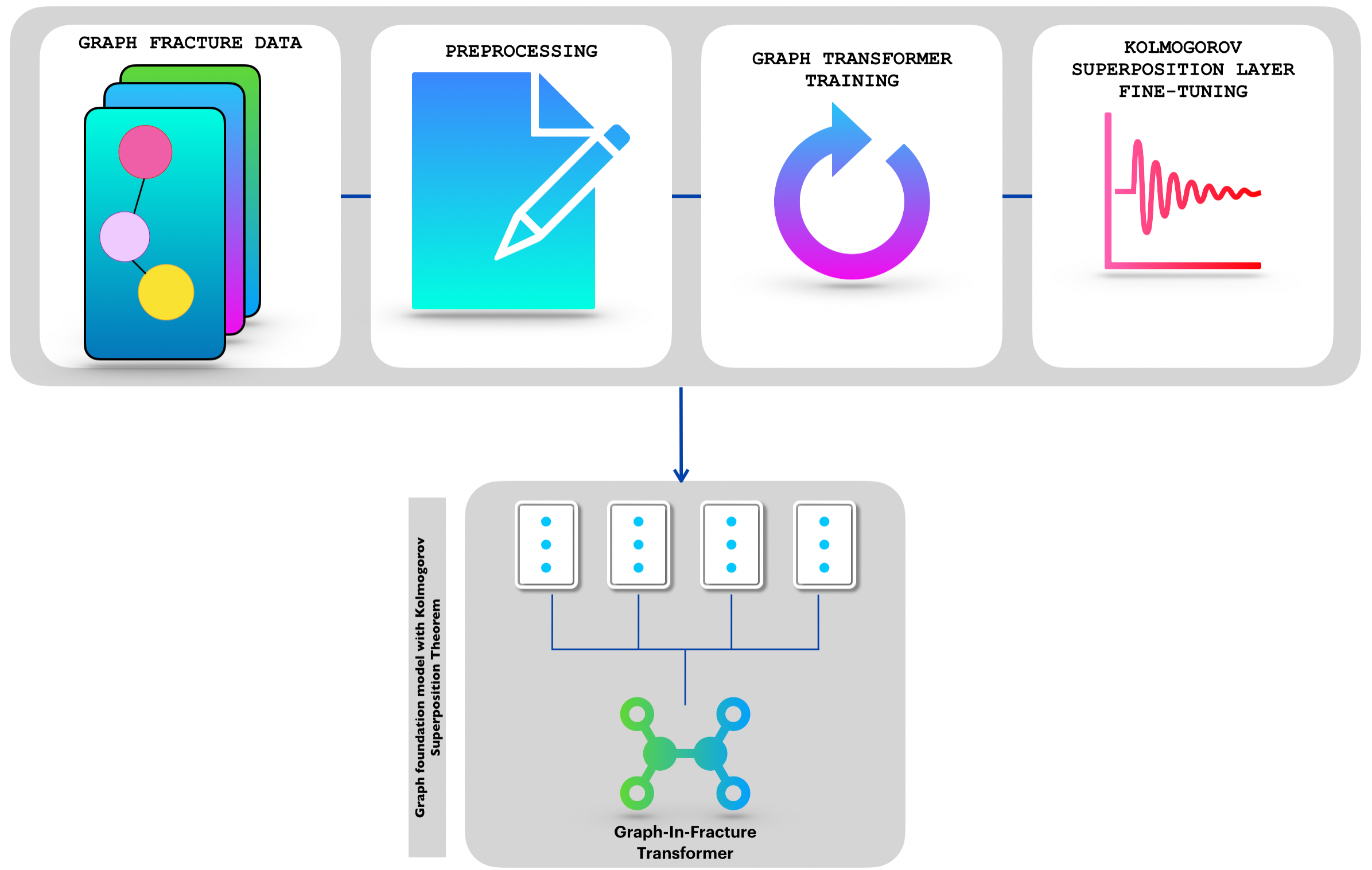
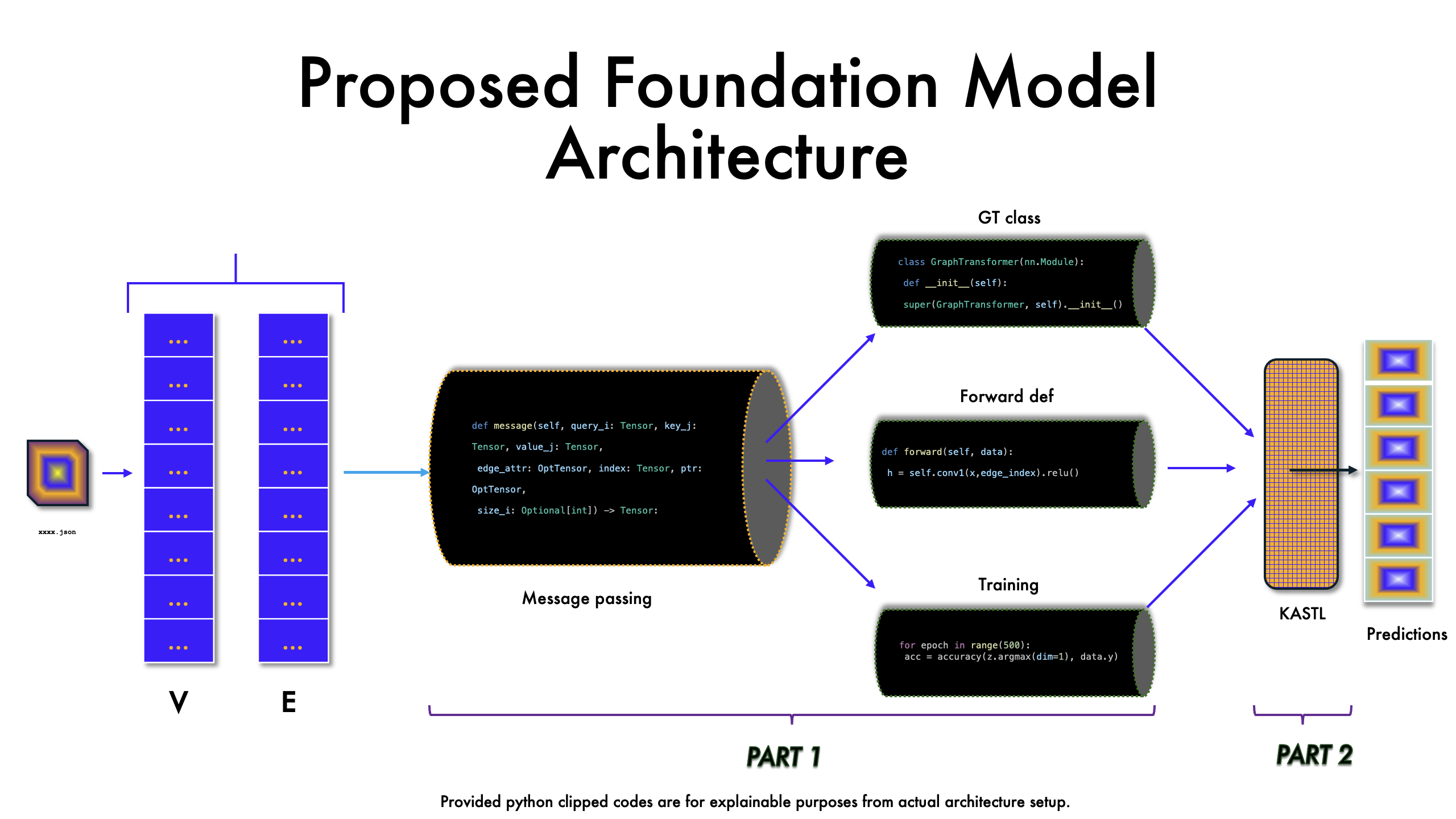
Graph Foundation Model for Scientific Porous Media Data
GIFT-KASTL
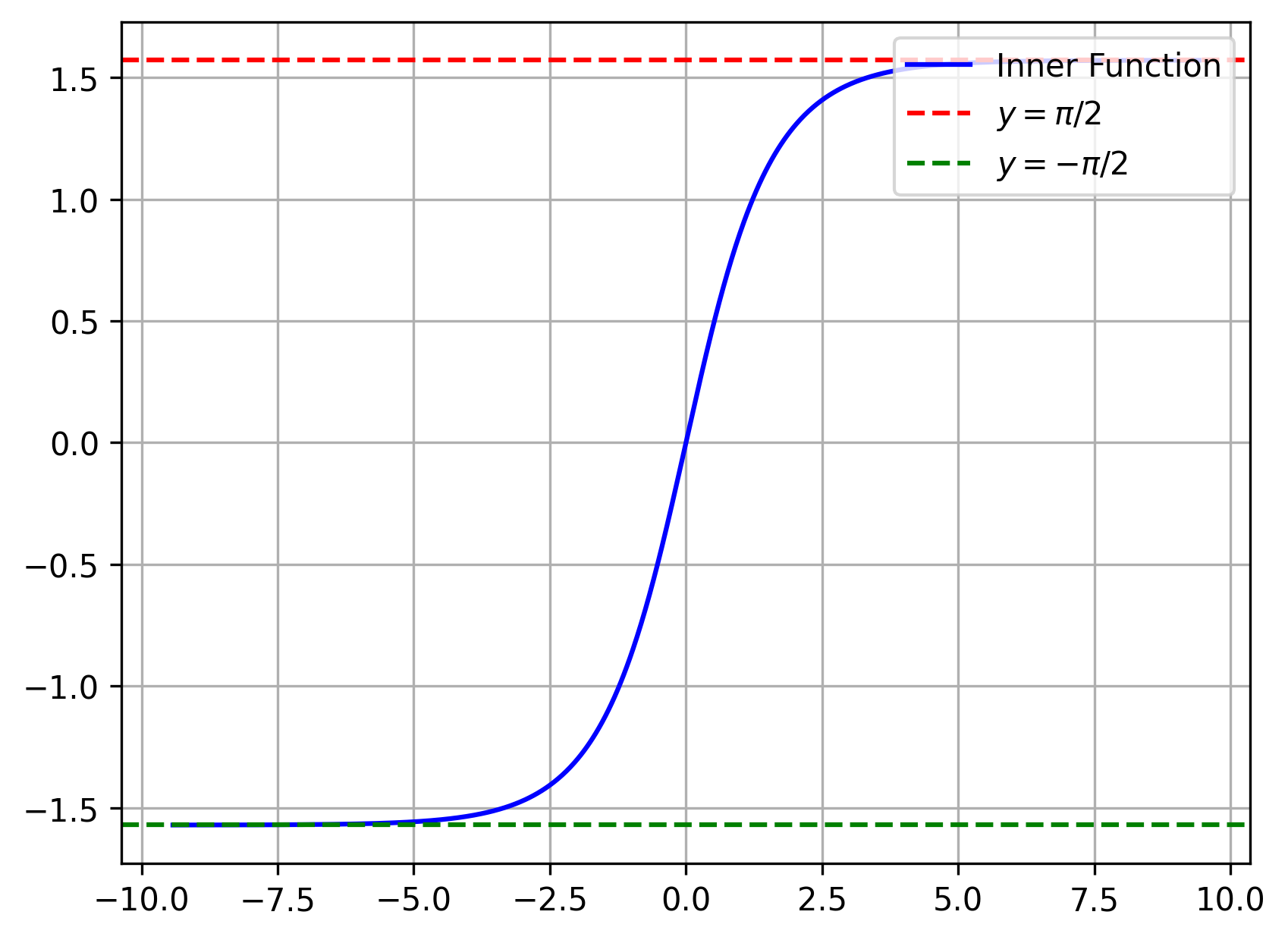
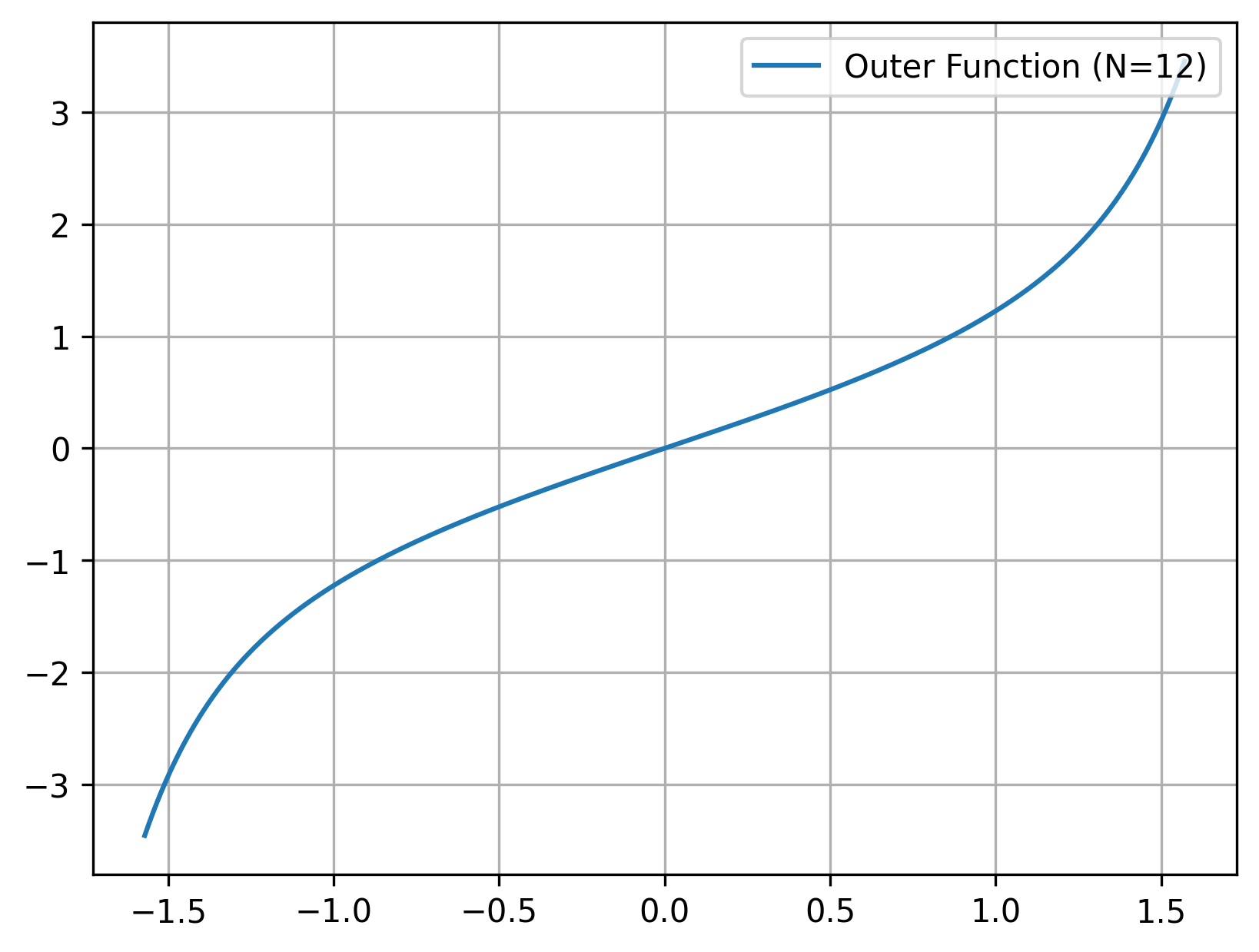
Graph-In-Fracture Transformer with a Kolmogorov-Arnold Superposition Layer
A graph foundation model for discrete fracture networks in porous media.
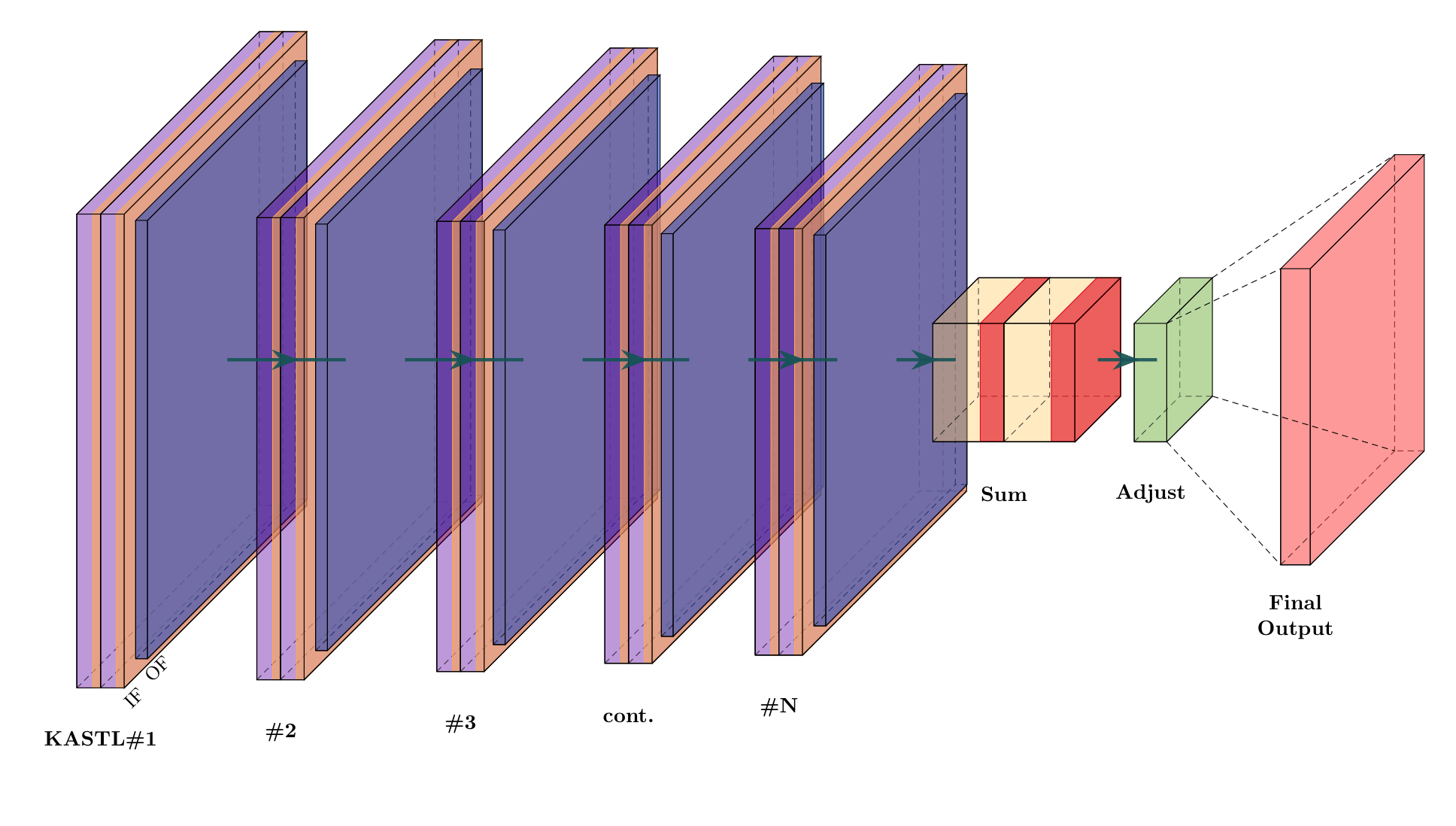
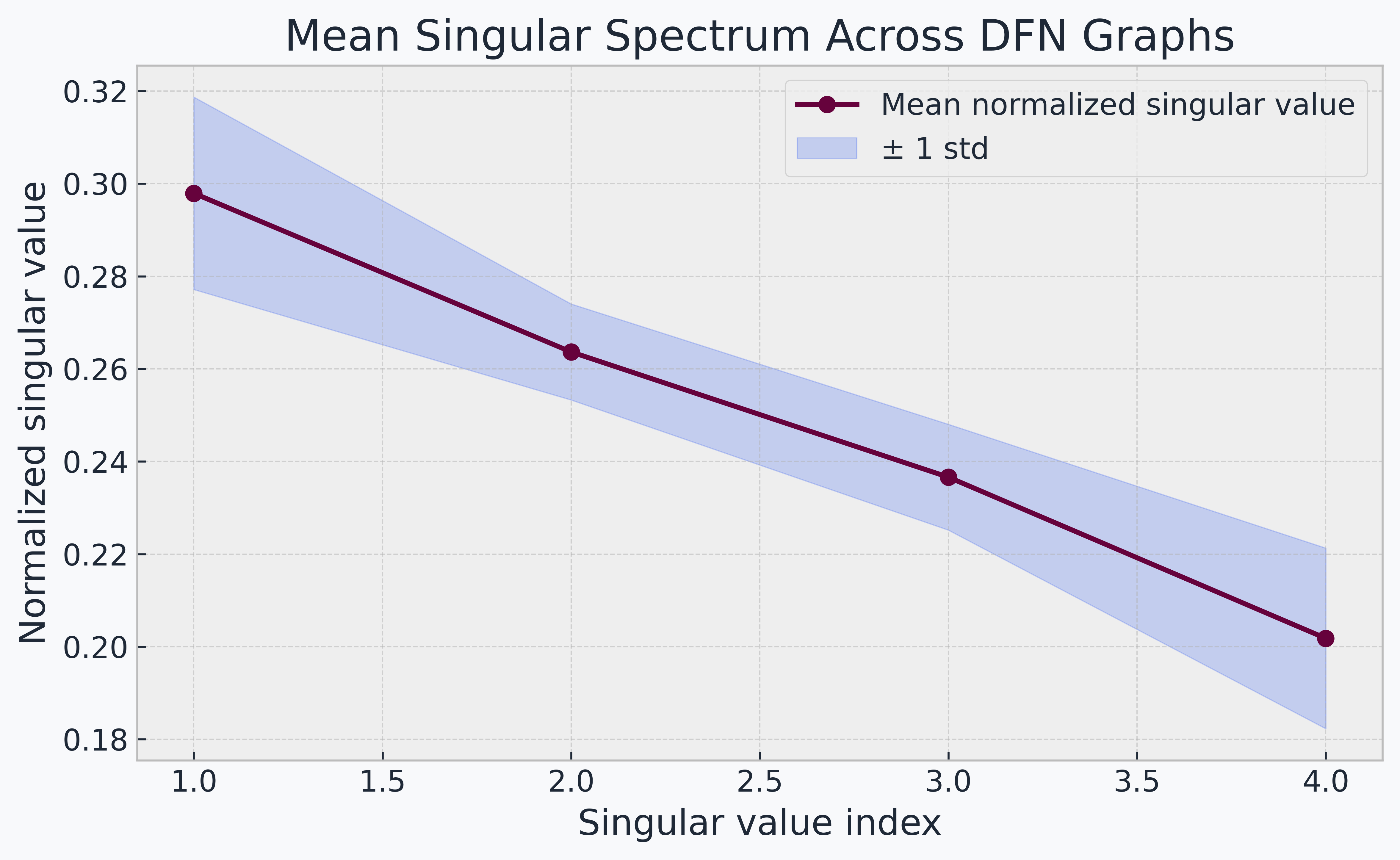
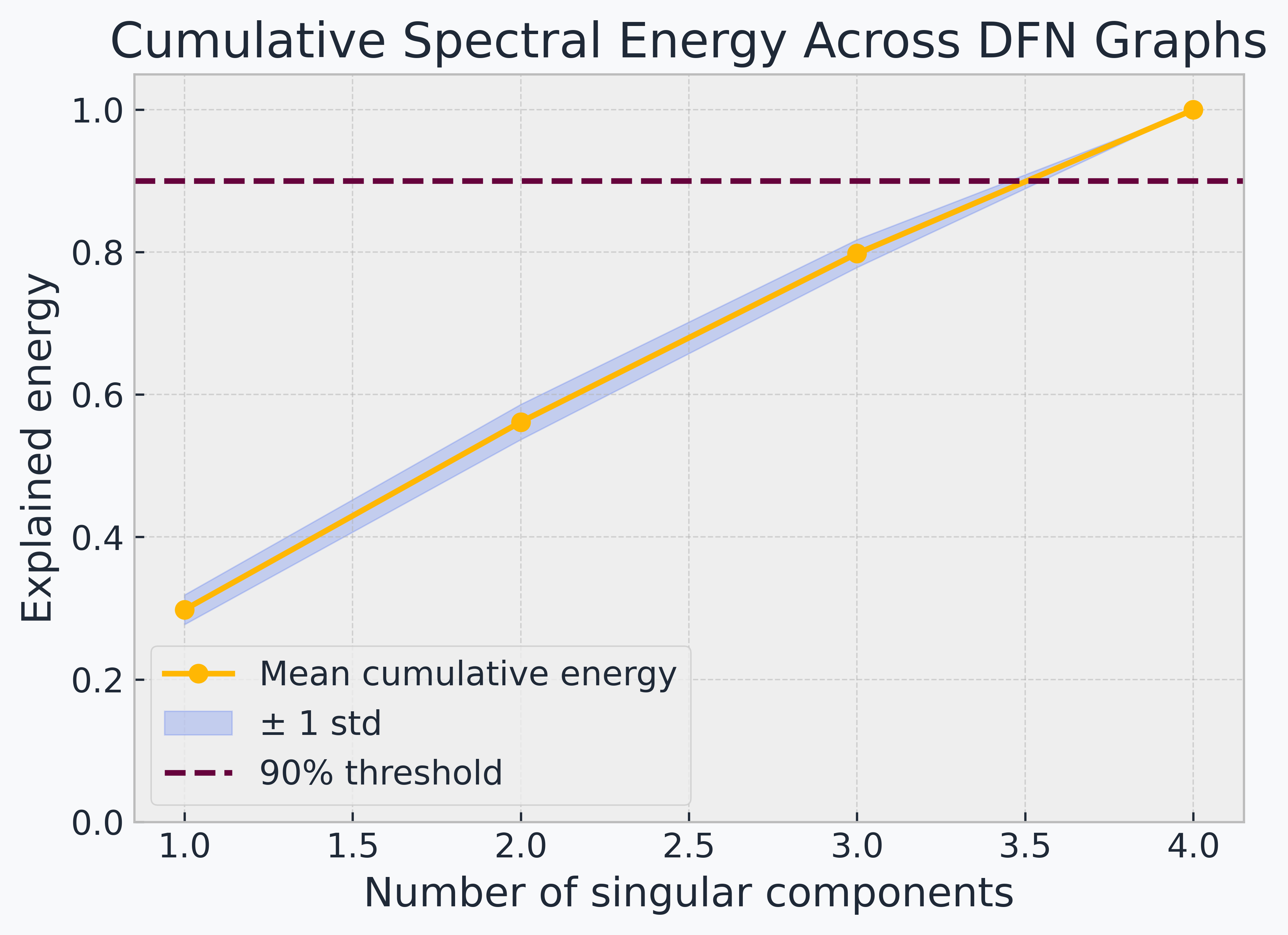
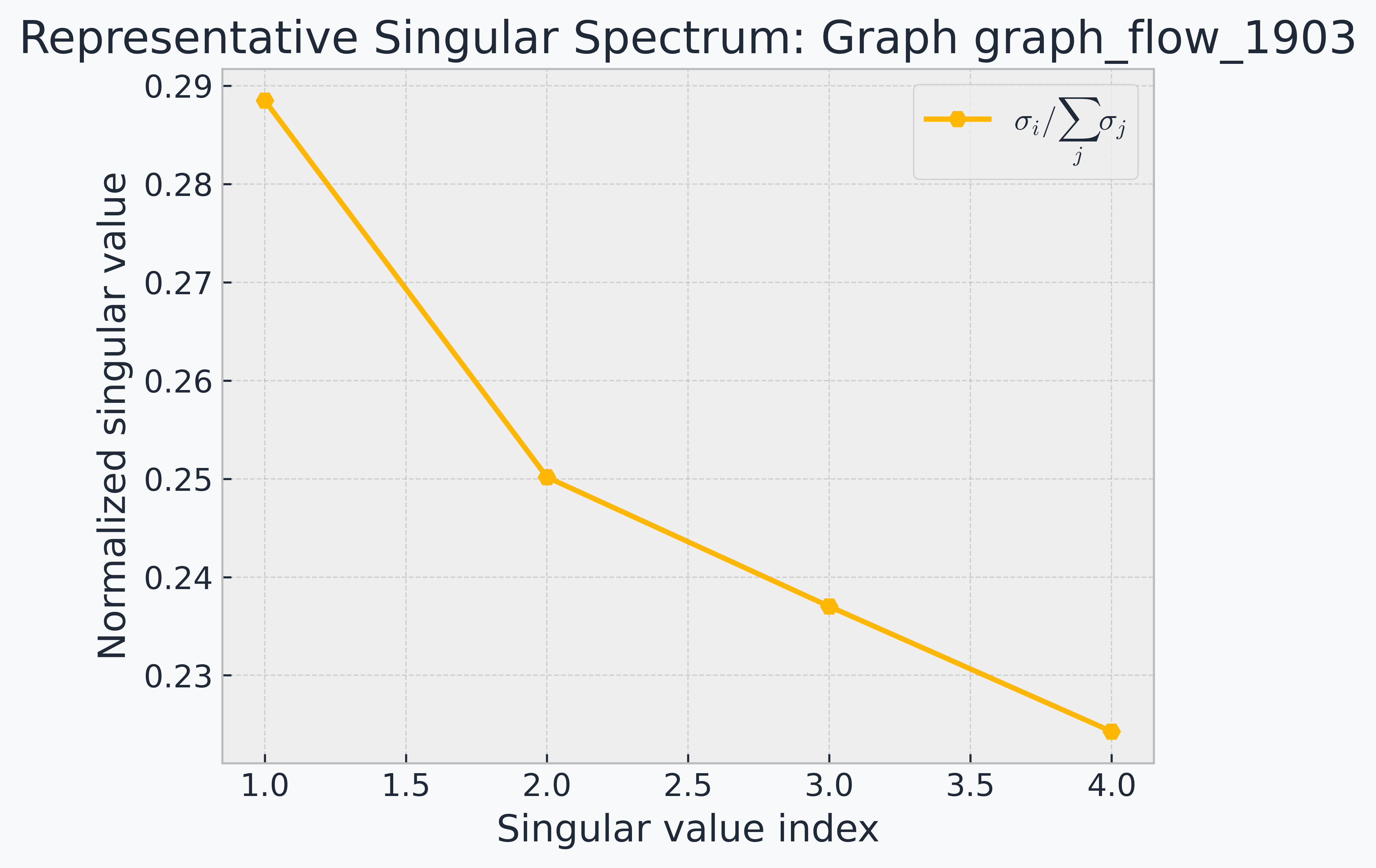
GIFT-KASTL combines a graph transformer backbone for graph-wide representation learning with a structured downstream refinement layer inspired by the Kolmogorov-Arnold Superposition Theorem. The goal is to model complex fracture-network data in a way that is expressive, scientifically meaningful, and architecturally disciplined.